CDASH and SDTM are each optimized for different purposes, and the philosophy behind each drives the design. SDTM represents cleaned, final CRF data organized in a predictable format that facilitates data transmission, review and reuse. CDASH collects the data in a user-friendly, EDC/CRF-friendly way that maximizes data quality and flows smoothly into SDTM. While most of the data is the same in both standards, each standard is designed for different purposes; therefore, differences do exist, both in philosophy and implementation.
Missing Data
Take missing data, for example. SDTM assumes the data is clean. Missing data is assumed to be verified; therefore, no placeholders appear in the datasets. This means that, if a subject had no adverse events (AEs) in the study, they will not be represented in the AE dataset. With CDASH, conversely, absence of evidence is not evidence of absence. No AE data received for a subject does not mean the subject experienced no AEs. It only means that no AE data was received, which must be verified. This is why CDASH includes indicator questions such as “Were any adverse events experienced?”
CDASH - Absence of evidence is not evidence of absence; must check that missing data is missing:
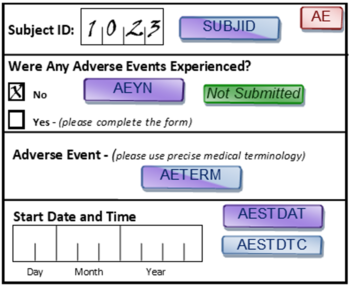
SDTM - Show me the data, not lack of data

Rationale
- SDTM assumes that if there is no record then nothing happened. This only works if no record was checked in data capture, which requires a question and record (e.g., Were there any AEs?)
Non-Standard Variables
Non-standard variables are another example. Every study includes questions that are not defined by CDASH. In SDTM, these questions go into a separate dataset and are linked to their “parent” data via a third dataset called RELREC. Consequently, extra variables can be stored predictably without changing the “parent” dataset design. In data capture, this set up is often clumsy, separating closely related variables onto different CRFs/screens. Instead, CDASH lets non-standard variables exist on the same record as the rest of the “parent” data, and RELREC is not used.
The following examples illustrate additional philosophical differences between CDASH and SDTM:
Human vs Machine Readable Data
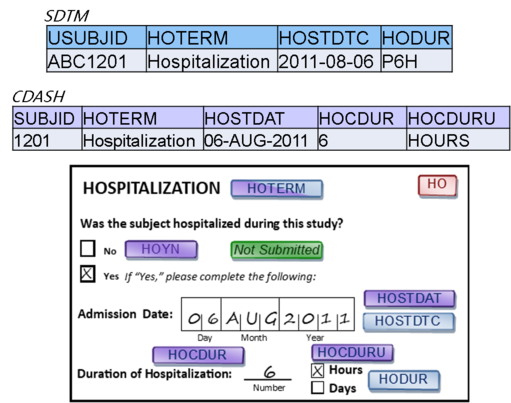
SDTM
Machine-readable: Dates/Times: ISO 8601, 1 variable, YYYY-MM-DDThh:mm:ss Duration: P1M3D
CDASH
Human-readable: Dates/Times: 2 or more variables, DD- MM-YYYY, HH:MM:SS Duration: 1 month, 3 days
Rationale
- SDTM machine-readable formats for variables, such as dates, are good for data reusability, but are not user-friendly for data capture. There is more chance for error when people record data in unfamiliar formats.
Data Organization
Each CRF should include the data that make sense to collect together. CDASH allows us to put variables for more than one domain on a CRF provided that standard variable names are used, and that, in the end, the data appear in the right domains. In SDTM, data MUST appear only in the correct domain.
CDASH – Data on each CRF is driven by what is captured together, not necessarily by domain.
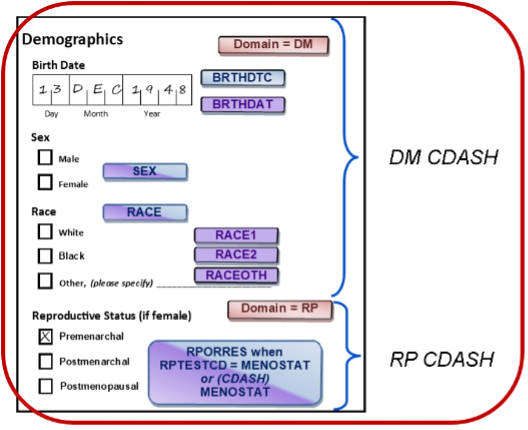
SDTM - Data must be organized into datasets by domain.
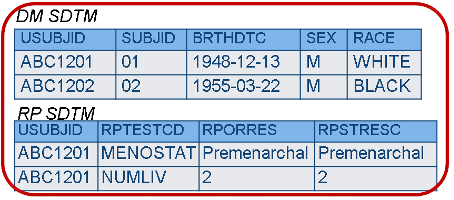
Rationale
- The CDASH philosophy is that data collection forms that mirror the way data are likely to be collected at the site, or appear in the patient’s electronic record, are more efficient for the site to complete, and thus more likely to result in higher quality data. With SDTM, however, the efficiency is gained by having reusable programs and other data structures, which is best supported by datasets that are as predictable as possible; in other words, the data must always appear in the expected places.
Horizontal vs. Vertical Data
There are types of data that have been modeled in SDTM such that one variable stores the question, and another variable stores the answer (e.g., questionnaires). This is how data appear in the Findings General Observation Class domains. In this case, each question may have its own different set of responses (i.e., its own codelist), which is fine, because by the time the data get to SDTM the answer is known, and there is only one value in the answer variable. When collecting the data, however, all the choices must be presented for each question, but in many systems, it is not possible to have more than one codelist associated with one variable. As a result, the CDASH structure may need to provide a different variable for each question, and the data would be transformed later.
EDC CRF

CDASH - Findings data may have to be horizontal for each test to have its own codelist; SDTM Controlled Terminology is used for variable names and CRF prompts.

SDTM Findings data must be in a normalized or vertical structure; answers are already known.
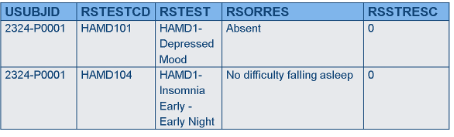
Rationale
- In normalized data, each test is on a different record and may need different controlled terms (this information is called “value-level metadata”), which cannot be modeled in most data capture systems; some EDC systems can’t handle normalized data at all.
Metadata Content
Metadata, or the information that describes the domains, is somewhat different for each standard.
CDASH - Metadata includes question text/prompt, CRF completion instructions, and SDTM mapping instructions (not shown).

SDTM - Metadata includes variable labels and roles.

Rationale
- SDTM focuses on tabulating data, and so defines the information necessary to support predictable “flat files”. CDASH addresses data capture needs and is designed to ensure clear questions that produce consistent answers. Because they have different purposes, some of their metadata differs.
Unavailable Variables
SDTM
- Some variables can only be derived after studies are complete. For example, USUBJID identifies a subject uniquely across all studies in a submission; if a subject participates more than once, the subject is supposed to have the same USUBJID. Technically, this means that USUBJID cannot be created until all the studies in the submission are complete. STRESC/STRESN are intended to hold values that have been standardized across the submission. These standard values may or may not be the units the sites use for data capture, which is why there is an --ORRES “original result” variable. Finally, EXTRT/EXDOSE represent the actual treatment the subject received, and in doubleblind studies, this will only be known after the blind is broken, which is obviously after the study is over.
CDASH
- Some variables have meaning only within the context of the study (e.g., SUBJID) is, by definition, an identifier that is unique only within the study. ECTRT/ECDOSE are variables that capture whatever is known about a blinded treatment during the study.
Rationale
- CDASH and SDTMI are designed for different, if overlapping, purposes, and each has variables that support its particular function. SDTM’s primary focus is pooling data for submission or warehousing, whereas CDASH’s primary focus is collecting data for individual subjects in individual studies.
CDASH contributes significantly to data traceability, integrity and quality. It isn’t another standard to be mapped to as the data progress to SDTM. CDASH is intended to guide data collection so that data flow easily from collection into SDTM. CDASH facilitates this by including the CDASH-to-SDTM mappings for all standard variables. If you have data in a non-standard format, it’s often easier to map to CDASH first because CDASH’s structure more closely mimics common collection approaches. You can then map to SDTM by following the instructions in the CDASH Implementation Guide.
A final thought: If you use SDTM to collect your data, by the time you have made all the changes that are necessary to accommodate data collection requirements, you have basically created CDASH, so why not just start with it?
Benefits of Using Both CDASH and SDTM
- Ensures you’re asking the same question and using the same answer lists from collection through analysis
- Optimizes the site’s data requirements and structure for transmission, analysis, review and reuse
- Supports traceability back through data collection
- Minimizes programming and validation resources and increases quality when transferring data from capture to tabulation
- Helps to “future-proof” the data for warehousing and other uses beyond the initial study